Working with Messy Spreadsheets
2021-03-15 Aaron Chafetz
corps munging wrangling processing
coRps Session on Messy Spreadsheets
Overview
At one point or another, we have all had to extract data out of a messy spreadsheet. We face a fork in the road when we decide how to handle this - do we adjust the spreadsheet to make it easy for us to read in or do we write more complicated code to ingest? The first option usually makes our lives easier in the short run, that we change some column names, unmerge some headers, and so on in the spreadsheet. The problem comes later on when you are given a new version of the file and have to replicate all your manual adjustments from memory in the exact same way. Or something comes up that calls into question the data - was it in the original or did it get messed up when you adjusted the file.
The more challenging option from the start is to figure out the load via coding it, but the benefit is that everything is documented and if you have to re-run with a new file, everything is good to go.
So, let’s talk through how to do this using R, which has some great packages to make your life a bit easier with this difficult task.
For today’s session, we’re going to do a similar walk through from a great blog post Miles McBain wrote back in 2017. The dataset is the same and we end with a similar result, but the process is slightly different (probably in large part due to the updates to these packages in the past 4 years).
Getting Started
To start, let’s download the messy spreadsheet that McBain covers from the Australian Bureau of Statistics. We want to grab the Australian Marriage Law Postal Survey 2017 - Participation spreadsheet. The data here is on the 2017 same sex marriage referendum in Australia.
Before importing a new dataset for the first time, its best to open it up and understand what you’re working with. What issues do you see with the spreadsheet?
McBain writes:
We have the electorate-level participation data for males and females inexplicably split across two gendered sheets. I preferred to start with just one sheet and work out a way to abstract my approach to both sheets later. For the first sheet I broke the problem down into two parts:
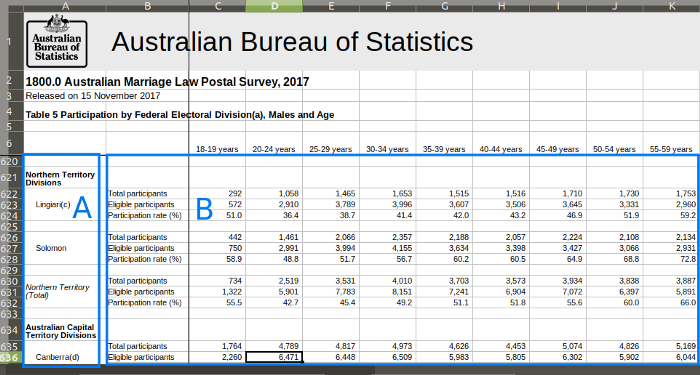
Dealing with A) and B) separately hinges on being able to read in separate data frames from areas within a sheet of an .xlsx file. Luckily the readxl package confers this ability. I split the problem because the merged cells worried me, and I thought it might lead to simpler code. See how for B) I only really need to worry about dropping rows that are all NA. I’ll also gather the data into long format so that age range is one covariate. While for A) I have to filter out the subheadings and remove the footnotes embedded in the electorate name.
As I mention, I’m going to go through a slightly different process and
keep this all into one piece, taking advantage of mutate() and
fill().
Data Time
Let’s load up the packages we’ll need to tackle this project.
library(tidyverse)
library(readxl)
library(janitor)
library(here)
Let’s try reading in the spreadsheet. We care about table 5 and 6, which share a similar structure. We’ll figure this out with table 5 and replicate with table 6.
file_name <- "australian_marriage_law_postal_survey_2017_-_participation_final.xls"
read_excel(
path = here("2021-03-15",file_name),
sheet = "Table 5") %>%
glimpse()
## Rows: 657
## Columns: 18
## $ `Australian Bureau of Statistics` <chr> "1800.0 Australian Marriage Law P...
## $ ...2 <chr> NA, NA, NA, NA, NA, NA, "Total pa...
## $ ...3 <chr> NA, NA, NA, NA, "18-19 years", NA...
## $ ...4 <chr> NA, NA, NA, NA, "20-24 years", NA...
## $ ...5 <chr> NA, NA, NA, NA, "25-29 years", NA...
## $ ...6 <chr> NA, NA, NA, NA, "30-34 years", NA...
## $ ...7 <chr> NA, NA, NA, NA, "35-39 years", NA...
## $ ...8 <chr> NA, NA, NA, NA, "40-44 years", NA...
## $ ...9 <chr> NA, NA, NA, NA, "45-49 years", NA...
## $ ...10 <chr> NA, NA, NA, NA, "50-54 years", NA...
## $ ...11 <chr> NA, NA, NA, NA, "55-59 years", NA...
## $ ...12 <chr> NA, NA, NA, NA, "60-64 years", NA...
## $ ...13 <chr> NA, NA, NA, NA, "65-69 years", NA...
## $ ...14 <chr> NA, NA, NA, NA, "70-74 years", NA...
## $ ...15 <chr> NA, NA, NA, NA, "75-79 years", NA...
## $ ...16 <chr> NA, NA, NA, NA, "80-84 years", NA...
## $ ...17 <chr> NA, NA, NA, NA, "85 years and ove...
## $ ...18 <chr> NA, NA, NA, NA, "Total Males(b)",...
We need to skip quite a few rows, 5 to be exact, since our table header start on row 6.
df <- read_excel(
path = here("2021-03-15",file_name),
sheet = "Table 5",
skip = 5)
df
## # A tibble: 652 x 18
## ...1 ...2 `18-19 years` `20-24 years` `25-29 years` `30-34 years`
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 New ~ <NA> NA NA NA NA
## 2 Banks Tota~ 1102 3098 2918 2895
## 3 <NA> Elig~ 1431 4224 4036 4188
## 4 <NA> Part~ 77 73.3 72.3 69.1
## 5 <NA> <NA> NA NA NA NA
## 6 Bart~ Tota~ 977 3047 3231 3678
## 7 <NA> Elig~ 1278 4186 4594 5305
## 8 <NA> Part~ 76.4 72.8 70.3 69.3
## 9 <NA> <NA> NA NA NA NA
## 10 Benn~ Tota~ 1177 3356 3106 3245
## # ... with 642 more rows, and 12 more variables: `35-39 years` <dbl>, `40-44
## # years` <dbl>, `45-49 years` <dbl>, `50-54 years` <dbl>, `55-59
## # years` <dbl>, `60-64 years` <dbl>, `65-69 years` <dbl>, `70-74
## # years` <dbl>, `75-79 years` <dbl>, `80-84 years` <dbl>, `85 years and
## # over` <dbl>, `Total Males(b)` <dbl>
Let’s add header to the missing columns and drop the total column. McBain adds the sex manually, but we’re going to extra it from the last column name in each table and use that. So we’ll extra the sex and then get rid of that column since its just a total.
tail(names(df), 1)
## [1] "Total Males(b)"
mf <- df %>%
names() %>%
tail(1) %>%
str_extract("(?<=Total ).*(?=\\()")
df <- df %>%
rename(area = ...1,
indicator = ...2) %>%
mutate(sex = mf) %>%
select(-contains("Total")) %>%
glimpse()
## Rows: 652
## Columns: 18
## $ area <chr> "New South Wales Divisions", "Banks", NA, NA, N...
## $ indicator <chr> NA, "Total participants", "Eligible participant...
## $ `18-19 years` <dbl> NA, 1102.0, 1431.0, 77.0, NA, 977.0, 1278.0, 76...
## $ `20-24 years` <dbl> NA, 3098.0, 4224.0, 73.3, NA, 3047.0, 4186.0, 7...
## $ `25-29 years` <dbl> NA, 2918.0, 4036.0, 72.3, NA, 3231.0, 4594.0, 7...
## $ `30-34 years` <dbl> NA, 2895.0, 4188.0, 69.1, NA, 3678.0, 5305.0, 6...
## $ `35-39 years` <dbl> NA, 2982.0, 4197.0, 71.1, NA, 3667.0, 5176.0, 7...
## $ `40-44 years` <dbl> NA, 3172.0, 4239.0, 74.8, NA, 3673.0, 4935.0, 7...
## $ `45-49 years` <dbl> NA, 3477.0, 4419.0, 78.7, NA, 3744.0, 4852.0, 7...
## $ `50-54 years` <dbl> NA, 3523.0, 4471.0, 78.8, NA, 3610.0, 4562.0, 7...
## $ `55-59 years` <dbl> NA, 3764.0, 4621.0, 81.5, NA, 3291.0, 4162.0, 7...
## $ `60-64 years` <dbl> NA, 3297.0, 3948.0, 83.5, NA, 2948.0, 3670.0, 8...
## $ `65-69 years` <dbl> NA, 2851.0, 3257.0, 87.5, NA, 2720.0, 3245.0, 8...
## $ `70-74 years` <dbl> NA, 2366.0, 2631.0, 89.9, NA, 2293.0, 2685.0, 8...
## $ `75-79 years` <dbl> NA, 1636.0, 1836.0, 89.1, NA, 1775.0, 1999.0, 8...
## $ `80-84 years` <dbl> NA, 1352.0, 1531.0, 88.3, NA, 1323.0, 1599.0, 8...
## $ `85 years and over` <dbl> NA, 1247.0, 1499.0, 83.2, NA, 1111.0, 1368.0, 8...
## $ sex <chr> "Males", "Males", "Males", "Males", "Males", "M...
Time to handle the areas. Merged cells from Excel are not machine readable so the the data are unmerged in R and stored in only the first cell.
df %>%
select(area)
## # A tibble: 652 x 1
## area
## <chr>
## 1 New South Wales Divisions
## 2 Banks
## 3 <NA>
## 4 <NA>
## 5 <NA>
## 6 Barton
## 7 <NA>
## 8 <NA>
## 9 <NA>
## 10 Bennelong
## # ... with 642 more rows
We can solve this by using tidyr::fill(), which by default will fill
down missing values.
df <- df %>%
fill(area)
df %>%
select(area)
## # A tibble: 652 x 1
## area
## <chr>
## 1 New South Wales Divisions
## 2 Banks
## 3 Banks
## 4 Banks
## 5 Banks
## 6 Barton
## 7 Barton
## 8 Barton
## 9 Barton
## 10 Bennelong
## # ... with 642 more rows
We can use a similar approach for the division, which are stored in Excel in the same row as the area. We want to capture those looking for any cells with division, creating a new column and then filling down.
df <- df %>%
mutate(division = case_when(str_detect(area, "Divisions") ~
str_extract(area, "^.*(?= Divisions)"))) %>%
fill(division) %>%
relocate(division, .before = 1) %>%
glimpse()
## Rows: 652
## Columns: 19
## $ division <chr> "New South Wales", "New South Wales", "New Sout...
## $ area <chr> "New South Wales Divisions", "Banks", "Banks", ...
## $ indicator <chr> NA, "Total participants", "Eligible participant...
## $ `18-19 years` <dbl> NA, 1102.0, 1431.0, 77.0, NA, 977.0, 1278.0, 76...
## $ `20-24 years` <dbl> NA, 3098.0, 4224.0, 73.3, NA, 3047.0, 4186.0, 7...
## $ `25-29 years` <dbl> NA, 2918.0, 4036.0, 72.3, NA, 3231.0, 4594.0, 7...
## $ `30-34 years` <dbl> NA, 2895.0, 4188.0, 69.1, NA, 3678.0, 5305.0, 6...
## $ `35-39 years` <dbl> NA, 2982.0, 4197.0, 71.1, NA, 3667.0, 5176.0, 7...
## $ `40-44 years` <dbl> NA, 3172.0, 4239.0, 74.8, NA, 3673.0, 4935.0, 7...
## $ `45-49 years` <dbl> NA, 3477.0, 4419.0, 78.7, NA, 3744.0, 4852.0, 7...
## $ `50-54 years` <dbl> NA, 3523.0, 4471.0, 78.8, NA, 3610.0, 4562.0, 7...
## $ `55-59 years` <dbl> NA, 3764.0, 4621.0, 81.5, NA, 3291.0, 4162.0, 7...
## $ `60-64 years` <dbl> NA, 3297.0, 3948.0, 83.5, NA, 2948.0, 3670.0, 8...
## $ `65-69 years` <dbl> NA, 2851.0, 3257.0, 87.5, NA, 2720.0, 3245.0, 8...
## $ `70-74 years` <dbl> NA, 2366.0, 2631.0, 89.9, NA, 2293.0, 2685.0, 8...
## $ `75-79 years` <dbl> NA, 1636.0, 1836.0, 89.1, NA, 1775.0, 1999.0, 8...
## $ `80-84 years` <dbl> NA, 1352.0, 1531.0, 88.3, NA, 1323.0, 1599.0, 8...
## $ `85 years and over` <dbl> NA, 1247.0, 1499.0, 83.2, NA, 1111.0, 1368.0, 8...
## $ sex <chr> "Males", "Males", "Males", "Males", "Males", "M...
There are a lot of extra rows - totals, footnotes and just blank rows for table spacing. Let’s remove the excess.
df <- df %>%
filter(!is.na(indicator),
str_detect(area, "Total", negate = TRUE))
Almost there. The last thing we need to do is make this a tidy dataset. Ages should be a column rather than each age group being its own column. And then we want the indicators to each be their own column.
df <- df %>%
pivot_longer(-c(division, area, indicator, sex),
names_to = c("age_group", NA),
names_sep = " ") %>%
mutate(age_group = if_else(age_group == "85", "85+", age_group))
df <- df %>%
pivot_wider(names_from = indicator,
values_from = value) %>%
clean_names() %>%
mutate(participation_rate_percent = participation_rate_percent/100)
df
## # A tibble: 2,250 x 7
## division area sex age_group total_participa~ eligible_partic~
## <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 New Sou~ Banks Males 18-19 1102 1431
## 2 New Sou~ Banks Males 20-24 3098 4224
## 3 New Sou~ Banks Males 25-29 2918 4036
## 4 New Sou~ Banks Males 30-34 2895 4188
## 5 New Sou~ Banks Males 35-39 2982 4197
## 6 New Sou~ Banks Males 40-44 3172 4239
## 7 New Sou~ Banks Males 45-49 3477 4419
## 8 New Sou~ Banks Males 50-54 3523 4471
## 9 New Sou~ Banks Males 55-59 3764 4621
## 10 New Sou~ Banks Males 60-64 3297 3948
## # ... with 2,240 more rows, and 1 more variable:
## # participation_rate_percent <dbl>
So we were able to get that to work with the male table. We can create a function from the work we did above so that we can run the same code over the two tabs.
extract_data <- function(file, tab){
df <- read_excel(
path = here("2021-03-15",file_name),
sheet = tab,
skip = 5)
mf <- df %>%
names() %>%
tail(1) %>%
str_extract("(?<=Total ).*(?=\\()")
df <- df %>%
rename(area = ...1,
indicator = ...2) %>%
mutate(sex = mf) %>%
select(-contains("Total"))
df <- df %>%
fill(area) %>%
mutate(division = case_when(str_detect(area, "Divisions") ~
str_extract(area, "^.*(?= Divisions)"))) %>%
fill(division) %>%
relocate(division, .before = 1) %>%
filter(!is.na(indicator),
str_detect(area, "Total", negate = TRUE))
df <- df %>%
pivot_longer(-c(division, area, indicator, sex),
names_to = c("age_group", NA),
names_sep = " ") %>%
mutate(age_group = if_else(age_group == "85", "85+", age_group)) %>%
pivot_wider(names_from = indicator,
values_from = value) %>%
clean_names() %>%
mutate(participation_rate_percent = participation_rate_percent/100)
return(df)
}
Et voila!
df_all <- map_dfr(c("Table 5", "Table 6"),
~extract_data(file_name, .x))
df_all
## # A tibble: 4,500 x 7
## division area sex age_group total_participa~ eligible_partic~
## <chr> <chr> <chr> <chr> <dbl> <dbl>
## 1 New Sou~ Banks Males 18-19 1102 1431
## 2 New Sou~ Banks Males 20-24 3098 4224
## 3 New Sou~ Banks Males 25-29 2918 4036
## 4 New Sou~ Banks Males 30-34 2895 4188
## 5 New Sou~ Banks Males 35-39 2982 4197
## 6 New Sou~ Banks Males 40-44 3172 4239
## 7 New Sou~ Banks Males 45-49 3477 4419
## 8 New Sou~ Banks Males 50-54 3523 4471
## 9 New Sou~ Banks Males 55-59 3764 4621
## 10 New Sou~ Banks Males 60-64 3297 3948
## # ... with 4,490 more rows, and 1 more variable:
## # participation_rate_percent <dbl>